When a machine shows symptoms, technicians need to figure out the root cause and the best way to fix it. Today, this knowledge lives in the heads of experienced engineers and is scattered across thousands of unstructured service reports of varying quality and languages.
Watch the 30-second summary
Auto-generated summary — read the full article below for details.
The lazy path (and why it fails)
You could have taken the easy path — throw everything into a RAG, plug an LLM on top, and call it a day.
But the reality of industrial data is different:
- A very specific glossary
- Rigorous instructions spread across many documents
- Domain-precise terminology
- Reports written in multiple languages, at multiple quality levels
The classical lazy approach just doesn’t cut it. The LLM gets confused, retrieval brings back noise, and you end up with a chatbot that sounds confident but says nothing useful.
So we thought a little bit more and built something meaningful.
What we designed and built in 3 days
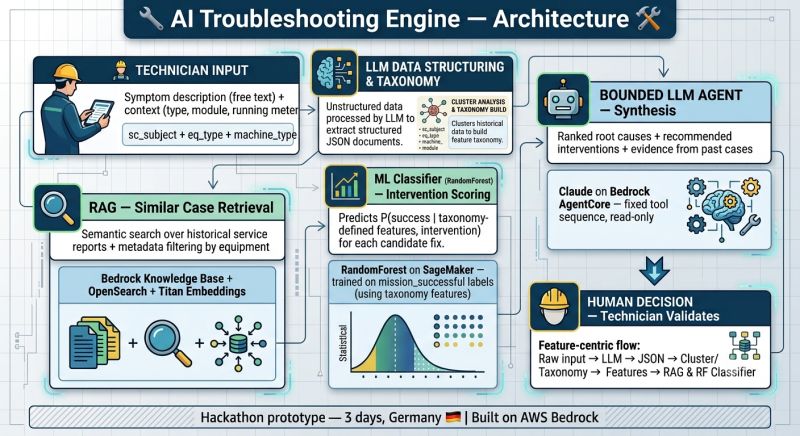
Here is the architecture we shipped:
- We converted thousands of unstructured reports into clean, normalized features
- We built a fault taxonomy using cluster analysis — no predefined categories, the data speaks
- We trained a Random Forest classifier and deployed it as a serverless endpoint on SageMaker AI
- We experimented with various chunking strategies, S3 Vectors, and Neptune for Graph RAG — because vanilla RAG has real weaknesses in this context
- We packaged everything as a tool for a Bedrock AgentCore agent that reasons over these features and provides human-readable explanations to the operator
Every experiment was systematically tested with AgentCore Evaluations to measure what actually improves performance — and what doesn’t.
The feature-centric flow
The pipeline follows a strict, feature-centric flow:
- Technician input → symptom description (free text) + context (type, module, running meter)
- LLM data structuring & taxonomy → unstructured data processed by LLM to extract structured JSON, then clustered to build the fault taxonomy
- RAG — similar case retrieval → semantic search over historical service reports with metadata filtering by equipment (Bedrock Knowledge Base + OpenSearch + Titan Embeddings)
- ML classifier — intervention scoring → RandomForest on SageMaker predicts P(success) for each candidate fix, using taxonomy-defined features
- Bounded LLM agent — synthesis → Claude on Bedrock AgentCore with a fixed, read-only tool sequence, producing ranked root causes and recommended interventions with evidence from past cases
- Human decision → the technician validates
The result
An operator describes the symptom. The agent retrieves similar past cases, scores the interventions by probability of success, and explains its reasoning.
Seconds instead of hours.
What 3 days can and cannot do
Three days is not enough to put this in production. But it’s enough to:
- Prove the concept works
- Automate document analysis, dataset construction, cleaning and normalization (yes, as a giant Jupyter notebook)
- Deploy and train on AWS instead of melting the laptop
- Fit everything into a working multi-agent system
- See the eyes of the engineers light up when the system finds in seconds what used to take hours of digging through archives
This was actually an optional goal of an even bigger project we built during these 3 days.
Key takeaways
- Vanilla RAG is not enough for industrial data — invest in a taxonomy
- Let the data define the categories (cluster analysis > predefined labels)
- Combine RAG with a classical ML classifier for scoring, not just retrieval
- Bound the LLM agent with a fixed tool sequence — reasoning, not improvisation
- Measure everything with agent evaluations, not vibes
- Keep the human in the loop — the agent proposes, the technician decides
Industrial AI is not about replacing engineers. It is about giving them back the hours they lose digging through archives.