
What is a code generator and data generator? This study provides you examples and research articles about several program automation research fields. This state of the art illustrates various use-cases where tools can be used to generate code and data to ease the coder’s life.
In my latest article, we have been reviewing Ponicode, an interesting young software company that promises to generate your Javascript tests. The results of test generation tools have been quite loudly discussed. I decided to produce a second article about the domain and what a tool can do to ease the life of a coder. I may discuss product/software for each category in the next post.
What can a tool generate for you?
Generating code from something has been a long time researched domain. Perhaps from the first day, humans began to code; some wanted to automate the process.
During my studies and my early professional life, I have been working and socializing with some of the best researchers and part of the team’s work what oriented about some specialized “code generation” subject fields. Despite not pursuing in the research domain, I created the Tocea company with a focus on automated code quality and security analysis and automatic code refactoring and migration.
A State of the art for the code generation tools ?
During the writing of the article; I tried to find some interesting materials about Automatic Programming or Code generation. I advise you to read the following resources :
- The state of the art in Code Generation
- Giorgi Gogiashvili : The State of the Art of Automatic Programming
I did not exactly find the resource I wanted. Especially about the reasons behind the need for code generation, apart from some specific use-cases. The next section will illustrate my own view on this matter.
Why would we need to generate code?
Several different reasons can bring the need to write a tool to generate some code or data for a code. The figure below is a summary of the reasons why would you need a code generation tool.
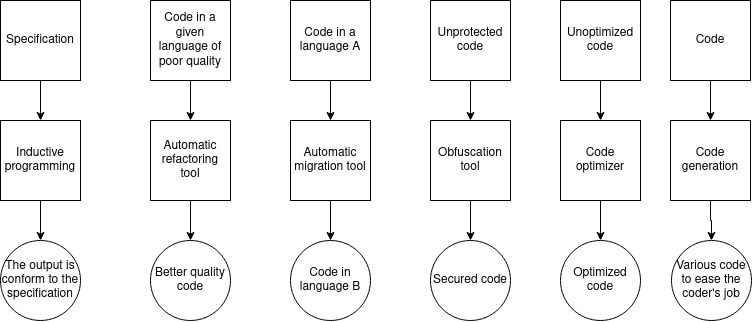
I cannot in a simple article list all kind of tools for each category, however, I will give you some samples :
Inductive programming
Under this term, you find the following concept (from this interesting resource) :
“The user says what to do, the computer builds a program that does it”
To be more precise, almost all tools using machine learning or deep learning fall under this category. After all, you are providing a dataset and you train a model that is basically the logic of your program.
If you are not convinced, have a look at this resource or these ones :
The following video is quite interesting too :
Automatic refactoring tools
I have been working for several years on this particular research field and my goal was the following one :
To secure an application, first and foremost the application has to be of good quality. What about the quality if the technical debt is too high? Let’s find an automatic way to refactor it.
This field has a lot of traction and you may find a lot of interesting resources about tools, prototypes, and methods.
Here’s a shortlist to spark your interest :
- 2014 : Manual Refactoring Changes with Automated Refactoring Validation
- 2011 : TrueRefactor : An Automated Refactoring Tool to Improve Legacy System and Application Comprehensibility
- 2017 : MultiRefactor: Automated Refactoring To Improve Software Quality
- 2009 : Automated Refactoring Suggestions Using the Results of Code Analysis Tools
- 2019 : Automatic software refactoring: a systematic literature review
Automatic migration tools
Another interesting field. Programs like all living creatures and all human creations are under the effect of time. They get old, erode, and ultimately will disappear. In computer science, an “old” application is also called a legacy application.
In order to save an application to fall in the legacy age, or in order to rejuvenate it, we may have to replace the technologies. We may call it software migration ( and the manual alternative The Big Rewrite).
Manually rewriting a software is a tedious and almost doomed challenge. Automation and tools decrease the risks, the costs at the compromise of a hybrid program that will keep scars from the old technology.
It exists a lot of tools that offer a way or another to convert an application into another application. Here are some examples :
Obfuscation and watermarking tools
This category of generation tools is self-explanatory. We want to protect our source code and our intellectual property. We have two categories of tools :
- The obfuscation tools make the code harder to read, decompile, and reverse-engineer.
- The water-marking tools are inserting mechanisms and signatures into your binary to keep a trace of the code.
Code optimizers
These tools are familiar to C/C++ developers. In most of our compiler, we have optimization routines, ie -o1, -o2, -p3 that are modifying our code ( at a different abstraction level or at the binary level). These tools offer automated code transformations to modify our program and make it more efficient.
Here are some interesting publications :
- Automatic validation of code-improving transformations on low-level program representations
- Efficient code generation for automatic parallelization and optimization
- Transformation Recipes for Code Generation and Auto-Tuning
- A Deep Learning Approach for Automatic Code Optimization in the Tiramisu Compiler
- Code optimization based on source to source transformations using profile guided metrics
Various use of code generation
Well, that is a quite exhaustive category. I didn’t find a proper term for the code generation assistants, wizards, and the MDA research field.
In this category, we may find the following kind of tools :
- tools to generate code based on models ( Model Driven Architecture ): an interesting presentation here and here.
- tools to generate code to achieve a certain result ( test generation )
When does the testing activity require automation ?
To ensure the functionality of a program, the accuracy of the results, timely answers and the system protection, the coder has to test its code. Testing a code may be a tedious process, long or expensive. That’s why, as a part of the code writing process, the test phase has always been a source of optimization (and I even prefer not to talk about Project manager that are skipping this development phase)
The need for tests has been artificially increased with the appearance of code coverage tools. By providing some metrics, they highlighted the program complexity and the cost to provide a decent test coverage. The metrics have been inserted in numerous contracts to push the quality forward with the contractors.
The code coverage may include several aspects of the program execution :
- lines of code
- branches of your program (if, else, while)
- predicates (true/false, etc)
- data boundaries
- faults and randomness
The entries in our program will greatly affect the execution and coverage of our code. And sometimes, to provide exhaustive data as inputs is complex.
Tools for Data / Input automatic generation
There is another field related to code generation is data generation. Most of our programs produce and consume data. The data our programs are using has various impacts on the code and its execution. Depending on the data consumed by the program; the execution may be slow, leading to invalid results or in some worst cases endangering the life of the users.

If we consider the ISO 9126 (old/deprecated quality model), there are several good reasons :
- we need data to make our application more secured
- we may even need data to be able to execute an unknown program
- we need data to emulate the program’s behavior in order to understand/replace it
- we need data to measure our program performance
Using data to secure a program
When we are talking about security, the data represents ( with some external factors) a source of unpredictability. The form and the nature of the data may cause crashes or unexpected behavior to the program. In this category, we will find the following tools :
- Fuzz-testing tools
- Fault Injection Security Tools
- SQL Injection tools
- Attack discovery tools
- Brute force/cracking tools
The following articles provide some useful insights about security and data generation tools.
- Evaluating Fuzz Testing
- Semi-valid Input Coverage for Fuzz Testing
- SECFUZZ: Fuzz-testing Security Protocols
- A systematic review of fuzzing based on machine learning techniques.
- NeuFuzz: Efficient Fuzzing With DeepNeural Network
- NEUZZ: Efficient Fuzzing with NeuralProgram Smoothing
Control the accuracy of the produced results / emulate the program’s behavior
We can include Ponicode from our previous article and all tools that are generating data to provide enough use-cases to test or to discover an application
According to Professor George Candea,
Research on automatic test generation has been carried out over many years and is still an active area of research. The techniques described in this article have been implemented in tens of tools. The application of those tools has, collectively, found thousands of new bugs, many of them critical from a reliability or security point of view, in many different application domains.
Another segment of tools that I have been rarely using is the test data generation tools. We often have the issue to generate test data for our mock databases in the integration tests. Of course, you can use a dump from your production. But you will have to run scripts to make the data anonymous. And sometimes the volume is also too large.
Test data generation tools help the testers in Load, performance, stress testing and also in database testing. Data generated through these tools can be used in other databases as well. This page provides a list of tools that I didn’t know.

You may also find these articles related to data generation and unit test generation interesting :
- Automated Software Test Generation:Some Challenges, Solutions, and Recent Advances by George Candea
- Does Automated Unit Test Generation Really Help Software Testers? A Controlled Empirical Study
- A Test Data Generation Tool for Unit Testing of C Programs
- Automated Unit Test Generation for Java
- Symstra: A Framework for Generating Object-Oriented Unit Tests using Symbolic Execution
- Automated Test Generation for Java Generics
- Jartege: a Tool for Random Generation of Unit Tests for Java Classes
- Automated Unit Test Generation for Classes with Environment Dependencies
- Scaling up automated test generation: Automatically generating maintainable regression unit tests for programs
Are these tools useful?
That is a pretty wide question because we need to answer it sincerely. I will separate my personal point of view in three parts :
- the functional point of view
- the economical point of view
- the ethical point of view
Avoid the expert tool trap
Yes, most of these tools are useful. A good tool is either easy to use or it is versatile: it can be used to address several problems.

As a rule of thumb, an code generation or data generation tool should have a clear and well-defined goal. A SQL injection tool is attempting to pass invalid data in the Web application to ensure no data has leaked. A non-regression test generator is generating a coverage of tests to prevent the application to insert regressions while refactoring it.
However, these tools have one frequent drawback. They are made by specialists for specialists. I will take one example to illustrate the difficulty to perceive the usefulness of an expert tool. Eclipse IDE then IdeaJ introduced refactoring functions some years ago. Most of these refactoring are designed from Martin Fowler’s wide literature.
The main issue with the refactoring tools is the relative anonymity of its usefulness. These functionalities are not know from all developers and some useful functions are used by a very limited set of coders.
Can we win money if we create such a tool?
There are a market and customers, therefore yes; we can win money. However, it is incredibly difficult. The developer tool market is an incredibly pressured market :
- developers build tools every day
- developers in your customer companies build tools
- developers are often reluctant to buy tools
- you will find a dozen free/open-source tools on the web
- your tool may be used only once depending on which problem is solved
- buying a tool is an expense and a LOT of companies thinks that it’s as bad as buying a better chair for a developer. But these companies are ready to invest millions in nearshore/offshore contractors.
- a lot of niche markets are dominated by some really big software editors backed by investment funds.
Often, the value of a paid tool is linked to its integration capacities. The ease to integrate with tools, languages, drivers, etc. Since the integration is really expensive, it provides for medium/large scale companies a quick and comfy way to use the tool in their environment.
Another way as a CEO is to plan carefully your exit. A lot of deep tech/software tooling startup is bought by someone else, few grows and stay viable. Therefore, as I mentioned before, do not try to integrate with everyone, it is too expensive. Target a perfect, natural, smooth integration with a well-known environment/ Saas provider / IDE that is backed by a company that has a track record of startup acquisition.
Ethics: can the coder job be automated? To which extent?
As a final word and as a conclusion, I would like to open the debate on the future of the coder job.
Without falling into extreme paranoia, advances in AI and frameworks now make it possible to generate programs from simple sentences or diagrams. We all felt uncomfortable to some extent with the advances of Facebook; Google etc. on automated code generation tools.
My philosophy is the following; if part of your work can be replaced by software, also written by another developer, it’s because the work you were doing was of little value and therefore easily automated. How many days, how many months do we waste writing code without any form of complexity? Who among us remembers the brutal efficiency of a Microsoft Access or Windev when writing a new analogous Angular application?
The professionalization and popularization of the computer science profession have created castes (a bit like Indian society). The lowest caste and the most numerous (but not pejorative), laboriously produce forms, CRUD, soulless REST APIs. At the top, we find the people who influence others, creating frameworks, tools, and threatening jobs below.
I think *everyone* should be able to write simple software, with the right tools, what we call Shadow IT. Excel, Access, VBA, Zoho Apps today fill this need and offer to everyone, the possibility to write software that will be of maximum utility because it is written by a person in the business. And this place should not be occupied by professional developers and we should avoid taking this kind of job, threatened in the future.
We should eventually work to industrialize, connect, and streamline these applications, once they have found their audience and write the Low-code, No-code tools and so on.
This will reduce the number of open positions but the challenges will be much more exciting.
Donate to the blog
[wpedon id=”1721″ align=”center”]